
Prevedere la siccità meteorologica
Previsione mensile dello SPI 3
Il sistema previsionale è basato su approccio empirico di previsione della siccità attraverso l’indice SPI 3, alcuni mesi in anticipo, attraverso indici climatici globali.
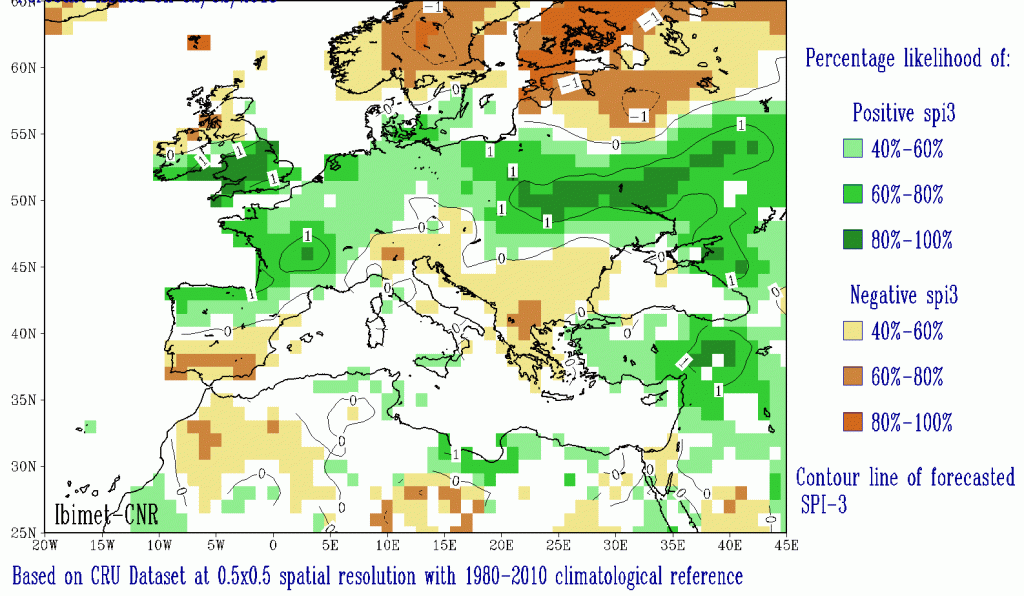
Previsione stagionale dello SPI 3 valida per Febbraio-Marzo-Aprile 2018. La scala di colori indica la probabilità di occorrenza di un periodo umido (verde) o secco (giallo-arancio).
Stimare la correlazione della siccità con Drivers a larga scala
Approccio statistico physically-based:
modello di Regressione Multivariata (RM) per predire anomalie future.
- Nella prima fase, viene usata una procedura a doppio step per selezionare il modello RM migliore in termini di performance predittiva, ovvero quali sono i drivers atmosferici a larga scala migliori (ed i loro ritardi) da usare come predittori per lo SPI-3.
- Nella seconda fase, vengono stimati i valori dei parametri del RM che riproducono la relazione lineare fra lo SPI-3 ed ogni driver in 1).
- Nella terza fase, le stime dei parametri ottenuti in 2) sono usate per predire le anomalie di SPI-3 future.
La procedura di de-trending è basata su una regressione non parametrica locale ed è inoltre applicata alla variabile dipendente.
Infine, il modello è composto da 12 matrici con 43 osservazioni, che sono i valori mensili delle serie temporali 1974-2015 e 13*5 predittori (essendo 13 gli indici e 5 passi temporali principali).
Inoltre, viene attuata una procedura di eliminazione delle variabili che risultano essere una combinazione lineare o avere una correlazione molto elevata con le altre variabili, al fine di risolvere il ben noto problma della multicollinearità nei modelli RM.
A questa matrice filtrata viene applicata una procedura a doppio step per selezionare il miglior modello in termini di performance predittiva:
- trovare gli otto migliori modelli per ogni gruppo da 1 fino a 12 predittori, corrispondente all’indice adjusted R2;
- trovare il miglior modello fra quelli identificati al punto (1) mediante un criterio di cross-validation in 10 ripetizioni e l’indice RMSE. L’intera procedura è stata fatta per ogni cella del dominio spaziale.
Indici climatici identificati come possibili predittori
Validazione del modello e performance predittiva
Riepilogo dei risultati
E’ stata fatta una valutazione della performance predittiva del miglior modello per ogni SPI-3, sommando i risultati ottenuti in ogni cella del grigliato. L’elevato numero di valori al di sopra di 0.5 è indice generalmente di una buona definizione del modello. Un tale comportamento è più evidente in inverno, quando la siccità può creare criticità maggiori. Una performance inferiore, invece, è stata identificata in estate, quando eventi siccitosi sono più comuni ed hanno impatti minori.
Validazione
Performance Predittiva
Riguardo al riepilogo dei risultati ottenuti in ogni cella del grigliato
signif 0.05 e signif 0.10 rappresentano la percentuale di predittori nel modello migliore che risultano individualmente significativi rispettivamente a livello α = 0.05 e α = 0.10 del t-test. adjR² e range RMSE sono il minimo e il massimo valore ottenuto in tutto il dominio spaziale; il range SPI è il minimo e il massimo valore osservato.